#패션 업체에서 마케팅을 담당하는 20대 직장인 김 모씨. 인공지능(AI) 덕분에 요즘 업무 부담을 크게 덜었다. AI가 인스타그램 같은 SNS에 '신상' 사진을 올릴 때 홍보 문구를 알아서 '척척' 작성해주기 때문이다. 요즘 젊은층이 쓰는 신조어도 문제 없다. '완내스(완전 내 스타일의 줄임말) 봄자켓'이란 문구를 AI가 자유자재로 활용한다.
네이버의 초대규모 인공지능(Hyperscale AI) '하이퍼 클로바'가 상용화했을 때의 모습을 가상으로 꾸며본 얘기입니다.
하이퍼 클로바는 네이버가 지난해 도입한 슈퍼컴퓨터를 바탕으로 개발한 AI 언어 모델인데요. 그 수준이 예사롭지 않습니다. 위의 사례처럼 신조어를 가지고 맛깔나게 글을 작성할 줄 알고 영어로 된 팝송 가사를 매끄러운 한국어로 번역할 수도 있습니다.
진화 속도는 갈수록 빨라지고 있습니다. 네이버는 이달부터 자사 임직원 업무에 하이퍼 클로바를 적용하고 향후에는 AI콜센터 등 다른 서비스로 활용 영역을 확대할 예정입니다.
사내 테스트 시작…점진적 상용화
성낙호 네이버 클로바 책임리더는 최근 한국과학기술단체총연합회 주최로 열린 AI 웨비나에서 '초대규모 AI의 기대와 현실 그리고 미래'라는 주제로 하이퍼 클로바에 대해 발표했는데요.

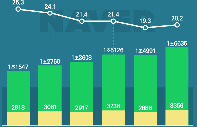
네이버는 현재 하이퍼 클로바 2040억개 파라미터 모델을 검증하고 있습니다. 파라미터란 AI 모델 크기를 나타내는 것으로 규모가 클수록 AI는 더 많은 문제를 해결할 수 있는데요.
초기에는 7억6000만개 파라미터 모델을 사용해 실험을 진행했습니다. 단계적으로 모델의 크기를 키워 820억개까지 검증을 완료했고요.
하이퍼 클로바에는 5600억 토큰(AI가 학습하는 데이터 단위)의 한국어 데이터가 사용됐다고 하네요. 미국의 비영리 연구 단체 오픈 AI가 개발한 초대규모 AI 언어모델 'GPT-3'에 들어간 한국어 데이터 대비 약 6500배에 달합니다.
또 기존 네이버 클로바 모델에 들어간 데이터의 3000배 규모입니다. 뉴스로 따지면 무려 50년치, 네이버 블로그로 따지면 9년치 데이터에 해당합니다.
이달 초 네이버는 하이퍼 클로바 스튜디오(개발 환경)의 사내 테스트를 시작했습니다. 네이버 직원들이 자연어 언어모델을 사용해 챗봇 개발 등 원하는 업무에 도움을 받을 수 있도록 도입했다는 것입니다.
네이버의 각종 서비스에 차근차근 적용하는 것이 최종 목표입니다. 이미 검색어 교정이나 쇼핑리뷰 요약 서비스에는 하이퍼 클로바 AI가 적용됐습니다. 네이버 클로바는 최종적으로 10여개 서비스에 적용할 수 있도록 준비하고 있습니다.
성 책임리더는 "현재 AI 기술이 발전되는 속도를 보면 반도체 산업 발전 속도와 크게 다르지 않다"며 "AI 하드웨어는 지속적으로 발전할 것이고 인터넷에 존재하는 데이터는 GPT-3가 사용하는 데이터보다 비교할 수 없을 정도로 크기 때문에 초대규모 AI 개발 추세는 멈추지 않고 진행될 것"이라고 말했습니다.
5분 만에 챗봇 만들고 가사도 번역하고
하이퍼 클로바를 활용하면 AI 챗봇을 단 몇분 만에 만들 수 있다고 합니다. 별도의 AI 학습 데이터셋을 제작하지 않고도 앞선 대화의 맥락을 이해해 대답하고, 사용자의 만족도를 인지해 호응하는 시스템을 만들 수 있는 것인데요. 캐릭터를 입힌 챗봇을 만드는 것도 몇 분 내로 가능합니다.

하이퍼 클로바는 글에 대한 감각이 남다릅니다. 예컨대 반려견, 반려묘 간식 제품 홍보 카피 문구 작성을 할 때 '댕냥이(강아지를 의미하는 댕댕이+고양이)와 함께하는 즐거운 식사시간' 등 신조어를 자유자재로 활용합니다.
성낙호 책임리더는 "기존 AI 모델로는 맛깔나는 말을 만들기 위해 데이터셋을 별도로 만들어야 한다"며 "이를 만드는 인력이 단순 인력이 아니고 전문가의 식견이 필요하기 때문에 만들기 어려운 데이터라는 점에서 의미가 있다"라고 강조했습니다.
AI콜을 만드는 작업 속도도 빨라집니다. AI콜을 만들기 위해선 하나의 의도(intent)마다 다양한 발화문을 수집해야 합니다.
예컨대 예약 변경을 요청한다는 상황을 가정할 때, 인원·시간·요일 변경 등에 해당하는 각양각색의 발화문('2시 예약인데 조금 일찍 가도 될까요?')을 모아야 하는 것인데요.
이런 정보를 기존에는 일일이 사람의 언어를 통해 수집해야 했는데요. 하이퍼 클로바는 그럴 필요가 없다고 합니다. 대화 시나리오 구축을 통해 스스로 발화문을 수없이 만들어 내니까요.
성 책임리더는 "대량으로 생산하는 데이터를 기반으로 더 작은 모델을 학습할 수 있게 됐다"며 "기존의 AI 개발 프로세스를 가속화할 수 있는 방법이 될 것으로 기대된다"고 말했습니다.
기존에 가능하지 않았던 일도 해냈습니다. '노래 가사 번역'은 기존 파파고와 같은 번역기가 제대로 하지 못하는 일 중 하나였는데요. 하이퍼 클로바는 문맥상 일관성을 유지하며 시적인 표현 등을 유려하게 번역하는 게 가능합니다.
낮은 학습 안정성 한계…막대한 비용 필요
과제도 많습니다. AI는 학습이 지속적으로 이뤄져야 합니다. 초대규모 AI도 마찬가지인데요. 이를 위해 대규모 데이터가 필요합니다.
학습 능력을 안정화 시키기 위해서는 초대규모·고품질의 데이터가 요구된다는 얘기입니다. 또 여기서 발생하는 오류로 시행착오를 겪을 때마다 어마어마한 비용이 들어갈 수밖에 없습니다.
성 책임리더는 "모델을 만들고 '이것보다 더 잘 만들 수 있지 않을까' 하는 실무진들의 아쉬움도 있다"며 "기존에 하던 파인튜닝을 (하이퍼 클로바에) 해보고 싶은데 모델이 너무 크다 보니 파인튜닝을 하는 것 자체가 비효율적이란 문제가 있다"고 말했습니다.